Rev. Fac. Agron. (LUZ). 1998, 15: 608-620
El an�lisis de conglomerados en la determinaci�n de regiones
homog�neas con base a la producci�n agr�cola de ma�z y sorgo en la regi�n zuliana
Cluster analysis in the determination of homogeneous regions based on the production of maize (corn) and sorghum in the zulia region
Recibido el 06-06-1997lAceptado el
02-09-1997
1. Centro de Estudios Geogr�ficos. Facultad de Humanidades y Educaci�n. La Universidad
del Zulia.
2. Centro de Estudios Matem�ticos, Facultad de Humanidades y Educaci�n. La Universidad
del Zulia, Apartado 526, Maracaibo, Venezuela. E-mail: [email protected]
3. Facultad de Agronom�a, La Universidad del Zulia.
Resumen
Palabras clave: Conglomerados, regiones, homog�neas, planificaci�n, agr�cola.
Abstract
Key words: Clusters,regions,homogeneity,planning,agriculture.
Introducci�n
Tradicionalmente, el paisaje natural ha sido subdividido en unidades espaciales definidas por la homogeneidad de factores f�sicos, como la topograf�a, suelos y vegetaci�n (2). Sin embargo, resulta de gran importancia dividir el espacio en unidades homog�neas con otro tipo de variables y t�cnicas de agrupamiento. La t�cnica de an�lisis de conglomerados puede ser de gran utilidad en estudios de diferentes escalas (local, regional, nacional) que consideren otros tipos de variables.
Bricker et al. (2) usaron las t�cnicas de an�lisis multivariado para resolver problemas de identificaci�n y clasificaci�n de comunicaciones en los Estados Unidos. Los citados autores trabajaron con formulaciones estad�sticas y an�lisis asociados con el problema de identificaci�n de personas utilizando como base la energ�a espectral representada por declaraciones ac�sticas. En ese trabajo se usaron dos cuerpos de datos, repartidos por repeticiones de declaraciones de palabras sueltas. El primer conjunto de datos estuvo formado por diez hablantes, cada uno de los cuales produjeron varias repeticiones de diez palabras corrientes usadas en conversaciones telef�nicas. El segundo cuerpo de datos se obtuvo por acuerdo con el primer grupo de hablantes, �stos �ltimos constituyeron una poblaci�n de 172 hablantes quienes repitieron los nombres de los cinco primeros d�gitos (uno, dos, tres, cuatro y cinco) cinco veces cada uno.
Chen et al. (5) utilizaron las t�cnicas de conglomerados para descubrir regiones homog�neas bas�ndose en la variable cantidad y tipos de compa��as industriales. Ese trabajo estuvo limitado a cuatro grandes grupos industriales - qu�micos, drogas, aceites dom�sticos y acero- especificado por sus est�ndares en los Estados Unidos. El agrupamiento se realiz� bas�ndose en la estructura y comportamiento de las firmas como miembros de grupos homog�neos para el desarrollo de ayudas para las mejores decisiones financieras concernientes a las operaciones de las firmas.
Lopes y Buarque de Lima (11) aplicaron el m�todo de an�lisis de conglomerados usando la distancia (euclidea) para clasificar 50 grandes ciudades de Brasil, utilizando como variables el nivel de desarrollo y el tama�o funcional de las urbes.
Casp y Bernabeu (3) realizaron el an�lisis de las caracter�sticas sensoriales de 16 vinos tintos de la denominaci�n de origen Valencia Uno, mediante el uso de t�cnicas estad�sticas multivariadas.
No es la intenci�n de este trabajo profundizar en la teor�a que sustenta el m�todo de los conglomerados, asunto que puede consultarse en trabajos especializados (6, 8, 10); sin embargo, se presentan las consideraciones b�sicas que permiten comprender sus t�cnicas al aplicarlo a un estudio de divisi�n del espacio geogr�fico en unidades homog�neas contiguas con base a rubros agr�colas. Este trabajo se realiz� con el prop�sito de realizar una delimitaci�n de regiones usando la producci�n de rubros agr�colas.
Materiales y m�todos
En este trabajo se aplica el an�lisis de conglomerados para determinar regiones homog�neas bas�ndose en la producci�n de ma�z y sorgo, para el a�o 1990, en la regi�n Zuliana. El estudio inicial contempl� otras variables agr�colas, para el per�odo 85-89. Sin embargo, para la elaboraci�n de este trabajo se revisaron, nuevamente, las estad�sticas en el Ministerio de Agricultura y Cr�a de la regi�n zuliana; es por esto �ltimo que una limitaci�n en las estad�sticas agr�colas obtenidas para realizar este trabajo debe ser se�alada. En efecto, las fuentes oficiales consultadas (12) s�lo registran informaci�n detallada por rubros agr�colas por municipios hasta 1991; a partir de 1992 la informaci�n es presentada de manera generalizada, esto es, sin considerar la divisi�n pol�tico territorial de la regi�n.
Los resultados obtenidos por cualquiera de los m�todos de agrupamiento, sea por agrupamientos sucesivos o por series de divisiones, pueden ser presentados en forma de un diagrama bi-dimensional conocido como dendograma o diagrama de �rbol (9).
Dentro de los m�todos de agrupamiento se consideran en particular, los denominados m�todos de enlace (linkage methods). Estos m�todos de enlace son adecuados para agrupar tanto registros como variables, proceso que no se da con otros m�todos de agrupamiento. Los criterios m�s conocidos de enlace son: el de vecino m�s cercano o m�nima distancia (single linkage), el de vecino m�s alejado o m�xima distancia (complete linkage) y el de la distancia media (average linkage) (10).
Para eliminar la variabilidad en el conjunto de puntos u objetos iniciales se ponderan las distancias obtenidas. Estas distancias permiten agrupar los casos seg�n criterios ya se�alados de vecino m�s pr�ximo, vecino m�s lejano, y distancia media.
En el primer paso del proceso de enlace se determina la matriz de las distancias y a partir de este punto se inicia un proceso que culmina con la ubicaci�n de los distintos puntos en grupos homog�neos dentro de s� y heterog�neos entre s�. La secuencia de trabajo definido como un proceso iterativo consiste en ubicar la distancia seg�n un criterio fijado inicialmente. Con la distancia se forma un primer grupo, el cual puede tener dos o m�s puntos o individuos o casos (6,9,10). La formalizaci�n matem�tica de este proceso se traduce en la sustituci�n de las filas y columnas respectivas por la fila y columna que pasan a representar al grupo, obteni�ndose as� una nueva matriz de distancias. Este �ltimo paso se repite hasta recomponer por similaridades todos los puntos de la matriz de datos originados (4, 6, 9, 10).
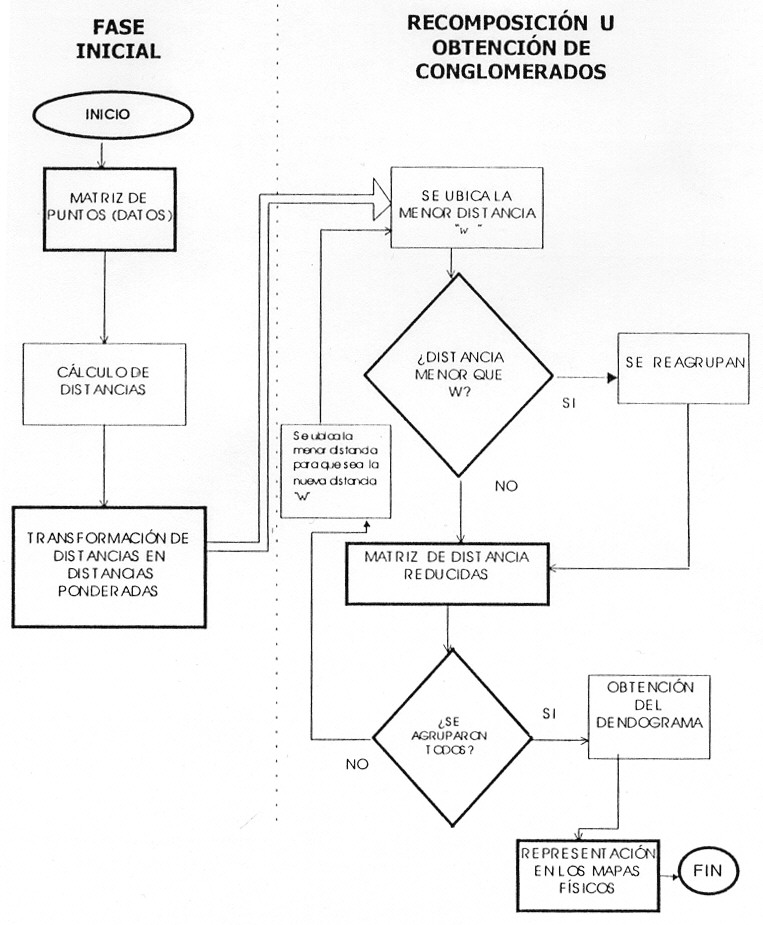
En este trabajo el criterio usado para determinar la cantidad de conglomerados, por escoger, fue �l de la distancia m�nima. La figura 1 contiene un diagrama de flujo de los procesos. Este algoritmo requiere los siguientes pasos:
Obtenci�n de la matriz de datos. El caso en estudio son dos variables econ�micas del sector agr�cola del estado Zulia. Se trabaj� con 17 registros de estas variables; porque s�lo se obtuvo informaci�n sobre ma�z y sorgo por municipio, los cuales constitu�an el modelo de divisi�n pol�tico - administrativa vigente para la �poca (cuadro 1). De ah� que, el arreglo de los datos es una matriz de 2x17, es decir, dos variables (producci�n de ma�z, producci�n de sorgo) y diecisiete observaciones para cada variable. Es importante aclarar que un diagrama de dispersi�n (7) de las regiones pol�ticas - administrativas da una primera aproximaci�n de clases de regiones; no obstante no proporciona elementos anal�ticos suficientes para agrupar las regiones m�s pr�ximas visualmente, con otras que se muestran en el gr�fico relativamente distantes (figura 2). La base de datos inicial se transforma en una matriz de distancias donde cada componente de la matriz constituye la distancia entre dos puntos o regiones pol�tico - administrativa las cuales, despu�s de aplicar la t�cnica, pueden resultar separadas o agrupadas.
Figura 1. Diagrama de flujo de los procesos.
Cuadro 1. Producci�n de ma�z y sorgo en el estado Zulia, por muncipio 1990.
| Municipio | Variables | |||
| (+) | (*) | Ma�z (t) | Sorgo (t) | |
| R1 | P�ez | B | 175,0 | 0,0 |
| R2 | Mara | A | 0,0 | 0,0 |
| R3 | Maracaibo | D | 0,0 | 973,72 |
| R4 | Jes�s E, Lossada | A | 0,0 | 0,0 |
| R17 | Insular Padilla | A | 0,0 | 0,0 |
| R5 | Ca�ada de Urdaneta | A | 0,0 | 0,0 |
| R6 | Rosario de Perija | A | 0,0 | 0,0 |
| R15 | Machiques de Perija | B | 165,00 | 0,0 |
| R7 | Catatumbo | A | 0,0 | 0,0 |
| R8 | Col�n | A | 0,0 | 0,0 |
| R9 | Sucre | A | 0,0 | 0,0 |
| R10 | Baralt | F | 2163,4 | 1358,0 |
| R11 | Lagunillas | A | 0,0 | 0,0 |
| R12 | Valmore Rodr�guez | A | 0,0 | 0,0 |
| R13 | Bol�var | A | 0,0 | 0,0 |
| R16 | La Rita | E | 281,6 | 941,6 |
| R14 | Miranda | C | 645,0 | 0,0 |
| Total | 3430,0 | 3273,32 | ||
Fuente: Unidad Estatal de Desarrollo Agropecuario,1991, MAC - Zulia. (+) Ubicaci�n de cada municipio. (*) Ubicaci�n en el diagrama de dispersi�n. (Figura 2).
C�lculo de las distancias entre los puntos del diagrama de dispersi�n. Existen diversas f�rmulas matem�ticas y estad�sticas para calcular estas distancias (4). Para este estudio el punto en el sentido geom�trico - euclideo no diverge de los atributos de cada localizaci�n; porque aceptamos que ambas est�n contenidas en un solo concepto (11).
Recomposici�n de los puntos o construcci�n de conglomerados. En este proceso de recomposici�n se ubican los puntos que se encuentran a una distancia menor de la distancia m�nima prefijada al nuevo grupo; enseguida se procede a fijar la fila y columna respectiva que reemplazar� las existentes. En otras palabras, una regi�n sustituye a las regiones que le son vecinas; porque aceptamos que la localizaci�n de un punto y sus atributos son lo mismo. El criterio para agrupar los vecinos, en este caso de estudio, se denomina el vecino m�s pr�ximo (4, 6, 9, 10). La distancia entre un conglomerado C1 el cual agrupa tres objetos, esto es A (ABC) y un objeto W se calcula mediante d C1 W = min {d AW, d BW, d CW}, donde d AW, d BW y d CW son distancias pr�ximas de los objetos A y W, los agrupamientos de los objetos B y W, y los agrupamientos C y W, respectivamente. Este paso se repite hasta que se agrupan los dos �ltimos conglomerados.
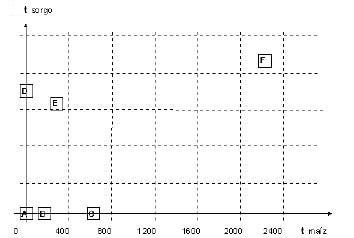
Figura 2. Diagrama de dispersi�n. Producci�n ma�z y sorgo (Estado Zulia).
Construcci�n del dendograma. Cada conglomerado que se forma despu�s de recomponer la matriz de distancia en cada iteraci�n o repetici�n del paso anterior se representa por un enlace hasta esa distancia.
Como ilustraci�n de este arreglo inicial se tiene el diagrama de puntos (figura 2), en el cual se aprecian los puntos entre los cuales se obtienen las distancias. Para este c�lculo se utiliz� la definici�n de distancia euclidea ponderada seg�n: d2 (A, B) = [(xA1 - xB1)/s1] 2 +[(xA2 - xB2)/s2]2 F1. donde: A es un punto con coordenadas (xA1, xA2) = (t ma�z regi�n A; t sorgo regi�n A) y B tiene coordenadas (xB1, xB2) = (t ma�z regi�n B; t sorgo regi�n B); s1 es el desv�o est�ndar para la variable X1 (t ma�z) y s2 es el desv�o est�ndar para la variable X2 (t sorgo).
Para los puntos representados en la figura 2, utilizando el paquete STATG (13), se producen las matrices de las distancias, las cuales fueron obtenidas para cada regi�n en relaci�n con las restantes usando la f�rmula F1, (10).
Aplicaci�n del algoritmo. Para obtener los conglomerados se aplic� la t�cnica denominada el vecino m�s pr�ximo, tal como se se�al� en los aspectos b�sicos de la Teor�a del An�lisis de Conglomerados.
El punto de partida para aplicar el algoritmo es la obtenci�n de la matriz de distancias. Para este trabajo se obtuvo la matriz de distancia inicial con todas las regiones pol�tico administrativas del estado Zulia (cuadro 2), donde cada valor que aparece en la matriz corresponde a la distancia entre dos puntos representados por las coordenadas que corresponden a la de producci�n de sorgo y ma�z de cada regi�n. Observando la matriz de las distancias se tiene que todas las distancias menores a 0,0 se dan entre las regiones: R2 y R4; R2 y R5; R2 y R6; R2 y R7; R2 y R8; R2 y R9; R2 y R11; R2 y R12; R2 y R13, y por �ltimo entre R2 y R17.
Resultados y discusi�n
La primera matriz de reducci�n de distancias se obtiene de la sustituci�n o reemplazo de las regiones R4, R5, R6, R7, R8, R9, R11, R12 , R13 y R17 por la regi�n R2. El resultado es una nueva matriz de distancias formada por R1, C1, R3, R10, R14, R15, R16, y R17, donde C1 es la recomposici�n u obtenci�n del conglomerado formado por los puntos R2, R4, R5, R6. R7, R8, R9, R11, R12, R13 y R17 (cuadro 3). En este cuadro, tambi�n, se muestra cual es el pr�ximo agrupamiento, el mismo esta indicado para los puntos o regiones R1 y R15. Esto se debe a que la distancia 0,0187 unidades es la menor entre todas las mostradas en el cuadro 3.
La figura 3 muestra la agrupaci�n C1 para conformar un conglomerado. Este �ltimo es el inicio de las iteraciones que permitir�n al finalizar las recomposiciones tener la forma definitiva en el dendograma (9, 10).
De acuerdo con el trabajo de recomposici�n se formaron dos conglomerados a una distancia menor de 4,3590 unidades. La figura 4 muestra una s�ntesis gr�fica de las nuevas agrupaciones ejecutadas.
La aplicaci�n del m�todo permite poner en evidencia con precisi�n estad�stica la existencia de dos regiones con caracter�sticas bien definidas, dedicadas a la producci�n de sorgo y ma�z. Dadas las caracter�sticas est�ticas de las variables consideradas, las inferencias obtenidas fueron enteramente descriptivas.
Seg�n los resultados obtenidos aplicando la t�cnica de an�lisis de conglomerados para determinar regiones homog�neas con base a la producci�n de ma�z y sorgo en la regi�n zuliana (1990), se formaron dos grupos de zonas si la distancia a considerar es superior a 4,3590 (figura 4) y tres grupos de regiones o zonas si la distancia es mayor que 2,2550 y menor que 4,3590 (figura 4).
Cuadro 2. Matriz de distancias con los puntos iniciales.
| R1 | R2 | R3 | R4 | R5 | R6 | R7 | R8 | R9 | R10 | R11 | R12 | R13 | R14 | R15 | R16 | R17 | |
| R1 | 0,0 | ||||||||||||||||
| R2 | 0,328 | 0,0 | |||||||||||||||
| R3 | 2,255 | 2,23 | 0,0 | ||||||||||||||
| R4 | 0,328 | 0,0 | 2,231 | 0,0 | |||||||||||||
| R5 | 0,328 | 0,0 | 2,231 | 0,0 | 0,0 | ||||||||||||
| R6 | 0,328 | 0,0 | 2,231 | 0,0 | 0,0 | 0,0 | |||||||||||
| R7 | 0,328 | 0,0 | 2,231 | 0,0 | 0,0 | 0,0 | 0,0 | ||||||||||
| R8 | 0,328 | 0,0 | 2,231 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | |||||||||
| R9 | 0,328 | 0,0 | 2,231 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | ||||||||
| R10 | 4,859 | 5,12 | 4,155 | 5,115 | 5,15 | 5,115 | 5,115 | 5,115 | 5,115 | 0,0 | |||||||
| R11 | 0,328 | 0,0 | 2,231 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 5,115 | 0,0 | ||||||
| R12 | 0,328 | 0,0 | 2,231 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 5,115 | 0,0 | 0,0 | |||||
| R13 | 0,328 | 0,0 | 2,231 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 5,115 | 0,0 | 0,0 | 0,0 | ||||
| R14 | 0,882 | 1,21 | 2,538 | 1,211 | 1,21 | 1,211 | 1,211 | 1,211 | 1,211 | 4,219 | 1,211 | 1,21 | 1,21 | 0,0 | |||
| R15 | 0,018 | 0,31 | 2,252 | 0,309 | 0,31 | 0,309 | 0,309 | 0,309 | 0,309 | 4,873 | 0,309 | 0,31 | 0,31 | 0,901 | 0,0 | ||
| R16 | 2,165 | 2,22 | 0,534 | 2,219 | 2,22 | 2,219 | 2,219 | 2,219 | 2,219 | 3,658 | 2,219 | 2,22 | 2,22 | 2,26 | 2,16 | 0,0 | |
| R17 | 0,328 | 0,0 | 2,231 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 0,0 | 5,115 | 0,0 | 0,0 | 0,0 | 1,211 | 3,09 | 2,22 | 0,0 |
Cuadro 3. Primera matriz de reducci�n de distancias.
| R1 | C1 | R3 | R10 | R14 | R15 | R16 | |
| R1 | 0.0 | ||||||
| C1 | 0,3285 | 0,0 | |||||
| R3 | 2,2550 | 2,2310 | 0,0 | ||||
| R10 | 4,8590 | 5,1156 | 4,1550 | 0,0 | |||
| R14 | 0,8823 | 1,2108 | 2,5384 | 4,2193 | 0,0 | ||
| R15 | 0,0187 | 0,3097 | 2,2524 | 4,8734 | 0,9011 | 0,0 | |
| R16 | 2,1653 | 2,2192 | 0,5339 | 3,6589 | 2,2614 | 2,1671 | 0,0 |
Con respecto a la formaci�n de tres grupos se obtuvo una estructura de nuevo ordenamiento, cuya caracter�stica en cada grupo es la siguiente:
1) El agrupamiento C5 uni� las regiones con una producci�n muy baja en ambos rubros de menos de 300 t y un caso para el cual la producci�n de ambos rubros fue de menos de 900 t.
2) El agrupamiento C4 cuenta con una producci�n que podr�a definirse como intermedia entre ambos grupos; la producci�n es entre 301 t y 950 t; en tanto que en la producci�n registrada en sorgo est� entre 901 t y 1000 t.
3) El agrupamiento formado por la Regi�n R10, representada por el muncipio Baralt, cuya producci�n de ma�z fue de 2.163,4 t y de sorgo de 1358 t durante el a�o 1990.
Para el caso de la formaci�n de dos grupos es posible advertir la siguiente estructura de reordenaci�n:
1) Los municipios del estado Zulia en los cuales la producci�n de ma�z fue menor a 2.163 t y con producci�n de sorgo de menos de 1358 t conforman el conglomerado C6.
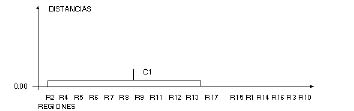
Figura 3. Dendograma para la primera matriz de reducci�n de distancias.
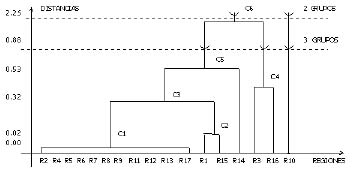
Figura 4. Dendograma con la agrupaci�n completa de las diecisiete regiones del Estado Zulia para los rubros agr�colas ma�z y sorgo. A�o 1990.
2) El municipio del estado Zulia con producci�n de ma�z de 2163,4 t y producci�n de sorgo de 1358 t conform� el segundo grupo homog�neo o Regi�n R10.
En general, �stos resultados muestran una regionalizaci�n homog�nea de acuerdo a los niveles de producci�n de los rubros agr�colas considerados. El municipio Baralt presenta la mayor producci�n de ma�z y sorgo con relaci�n al conjunto formado por el resto de los municipios del estado Zulia. Los municipios La Rita y Maracaibo muestran una producci�n entre 900 t y 1000 t de sorgo. El resto de los municipios del estado Zulia registraron una producci�n muy baja del rubro ma�z, entre 0,0 t y 650 t, en tanto que para el rubro sorgo, no hay registros de producci�n para el a�o seleccionado.
La figura 5 muestra una representaci�n cartogr�fica en la cual es posible observar las dos regiones homog�neas obtenidas de la aplicaci�n de la t�cnica de an�lisis de conglomerados. La Regi�n 1 representada por el municipio Baralt y la Regi�n 2 representada por los 16 municipios restantes del estado Zulia, para el a�o 1990.
De la aplicaci�n de la t�cnica de an�lisis de conglomerados se obtuvo no s�lo la estructura de los grupos, sino que la misma corresponde a las caracter�sticas de los municipios eminentemente agr�colas como es el caso del municipio Baralt (R10), y de escasos o medianamente agr�colas, representado por el resto de los municipios.
El trabajo demuestra el poder anal�tico y de s�ntesis de la t�cnica de conglomerados que permiti� clasificar el espacio geogr�fico en regiones homog�neas, con base a la producci�n agr�cola de ma�z y sorgo.
Una de las contribuciones del m�todo es la obtenci�n de regiones homog�neas del estado Zulia con base a la producci�n de las variables agr�colas estudiadas, la t�cnica aporta otras contribuciones. As�, a partir de la regionalizaci�n resultante de la aplicaci�n de la t�cnica de an�lisis de conglomerados se pueden iniciar nuevas investigaciones. Usualmente, un trabajo de geograf�a concluye con una descripci�n del m�todo por unidades espaciales homog�neas, en la cual la regionalizaci�n resultante se deriva de los criterios, generalmente operativos, los cuales se�alan objetivos de futuras actuaciones. De aqu�, que cuando la regionalizaci�n homog�nea refleja una determinada zonificaci�n, los organismos de planificaci�n en su b�squeda por ser cada vez m�s eficaces, deber�n considerar la posibilidad de trabajar con regionalizaciones peri�dicas que permitan posteriormente hacer estudios para planificaciones agr�colas seg�n las caracter�sticas de la regi�n pol�tico-administrativa y las necesidades poblacionales.
Cuadro 4. Clasificaci�n de municipio pol�tico-administrativos.
| Grupo | Agrupados | observaciones del nuevo grupo (frecuencia) | Distancia m�nima (similaridad) | Grado de generalizaci�n | Regi�n | Municipio (divisi�n pol�tico-administrativa) |
| C1 | 11 | 11 | 0,00 | 0,0 | 1 | R2: Mara |
| (0,0) | R4: Jes�s E. Lossada | |||||
| R5: Ca�ada de Urdaneta | ||||||
| R6: Rosario de Perija | ||||||
| R7: Catatumbo | ||||||
| R8: Col�n | ||||||
| R9: Sucre | ||||||
| R11: Lagunillas | ||||||
| R12: Valmore Rodr�guez | ||||||
| R13: Bol�var | ||||||
| R17: Insular Padilla | ||||||
| Se integran once regiones para formar C1 | ||||||
| C2 | 2 | 2 | 0,0187 | 0,828 | 1 | R1: P�ez |
| (0,01322) | ||||||
| R15: Machiques de Perija | ||||||
| Se unen dos regiones para formar C2. | ||||||
| C3 | 2 | 13 | 0,3285 | 14,55 | 1 | C1 y C2 |
| (0,2322) | ||||||
| Se unen C1 con C2 para formar C3. |
Cuadro 4. Continuaci�n.
| Grupo | agrupados | observaciones del nuevo grupo (frecuencia) | Distancia m�nima (similaridad) | Grado de generalizaci�n | Regi�n | Municipio (divisi�n pol�tico -administrativa) |
| C4 | 2 | 2 | 0,5339 | 23,67 | 2 | R3: Maracaibo |
| (0,3775) | ||||||
| R16: Cabimas | ||||||
| Se forman dos grupos C3 y C4 (uni�n de las regiones R3 y R16) | ||||||
| C5 | 2 | 14 | 0,8823 | 15,73 | 1 | C3 |
| (0,2510) | ||||||
| R14: Miranda | ||||||
| Se forma un grupo C5 (uni�n de C3 con R14) | ||||||
| C6 | 2 | 16 | 2,2556 | 100 | 1 | C4 y C5 |
| (1,5949) | ||||||
| Se forma un grupo C6, con la uni�n de C4 y C5 | ||||||
| En general, se forman dos grupos con C6 y R10 | ||||||
| C7 | 1 | 1 | 4,1550 | |||
| (2,938028) | Se agrupan todos con R10: BARALT |
Literatura citada
1. Bara, T., 1994. Gis-Based regionalization of natural landscape using derived landcover occurrence probabilities. p 34-43. In: Proceedings of the 1994 anual conference and exposition on GIS/LIS, Arizona, USA.
2. Bricker P.D., R. Gnanadesikan, M. V. Mathews, M. Pruzansky, P Tukey , K. Wachter and J. Warner. 1971. Statistical techniques for talk identification. J. Am. Telep. and Telegr. 50 (4): 1427-1454.
3. Casp A. y A. Bernabeu. 1987. Caracterizaci�n sensorial de los vinos de la denominaci�n de origen Valencia Uno. Vinos tintos. Rev. Agroqu�m. Tecnol. Aliment. 27(2): 237-245
4. Cormack A. D. 1971. A review of classification. J. Roy. Stat. Soc. Series A. 134: 321-367.
5. Chen H, R. Gnanadesikan and J. Kettenring. 1974. Statistical methods for grouping corporations. Sankhy�. The Indian Journal of Statistics 36 (serie B): 1-28.
6. Cuadras, C.M. 1991. M�todos de an�lisis multivariante, Editorial PPU, Barcelona
7. Fischer S, R. Dornbusch y R. Schmalensee. 1991. Econom�a. 2 edici�n. Editorial Mc Graw-hill, Madrid.
8. Gordon, A.D. 1987. A review of hierarchical classification. J. Roy. Stat. Soc. (A). 150. p:119-137.
9. Hartigan J.A. 1967. Representation of similarity matrices by trees. JASA. 62: 1140-1158.
10. Johnson R. and Wichern. 1982. Applied multivariate statistical analysis. Prentice - Hall, Englewood Cliff. New Jersey.
11. Lopes, M. y Buarque de Lima, O. 1978. Tend�ncias atuais na geografia urbano/regional. Compilado por faissol S. Funda�ao instituto Brasileiro de geografia e estatistica. IBGE. Rio de Janeiro p 113-124
12. Ministerio de Agricultura y Cr�a (MAC). 1991. Unidad estatal de desarrollo agropecuario (UEDA) y Divisi�n de Planificaci�n Agr�cola, Regi�n Zuliana. Estimaciones de producci�n agr�cola
13. Statistical graphics corporation, 1992, Statistical Graphics System, versi�n 6, Manugistic, Cambridge, Estados Unidos (STATG).